Editor's note: Deep Convolutional Neural Networks are a good model for the visual system, but these static systems cannot explain the short-lived dynamic behavior in real visual responses. So neuroscientists built a task-based deep recurrent network, adding recurrent units can solve more difficult vision problems. The following is a compilation of Lunzhi.

Summary
Feedforward Convolutional Neural Network (CNN) is currently the most advanced tool for object classification tasks, such as ImageNet. In addition, they are a model that accurately quantifies the average response time in the visual system of the primate brain. However, two ubiquitous structural features of the biological visual system are not available in a typical CNN, namely, the local circulation in the cortical region and the long-distance feedback from the downstream region to the upstream region. In this article, we studied the role of loop structure in improving classification performance. We found that in ImageNet tasks, standard loop forms (vanilla RNN and LSTM) cannot achieve good performance in deep CNN. On the contrary, a structure that combines two structural features—bypassing and gating—can greatly improve task accuracy.
We applied these design principles to the automatic search in thousands of models, and they determined that the local loop unit and the long-distance feedback connection are useful for target recognition. In addition, these task-optimized convolutional RNNs can better explain the activity of neurons in the primate nervous system than feedback networks, indicating that the circulatory connections of the brain are very important when performing different visual actions.
Background introduction
The brain's sensor system must detect meaningful patterns in complex sensory data containing noise. The visual environment can reveal the positive or negative value of an object, such as the type of food, danger signals, or memorable people. However, the position, posture, background and foreground of these signals in different scenes are very different, so it is difficult to distinguish the target object from low-attribute images.
Recent studies have shown that the task-optimized deep convolutional neural network (CNN) is an accurate quantitative model of the visual encoding of the primate brain. CNN is trained to recognize objects in ImageNet, and it can explain neuronal feedback in the visual system better than other models. The resolution of each convolutional layer of the model provides linear prediction of different visual areas.
However, some structures of the primate visual system are not completely imitated by the feedforward CNN, that is, the local cyclic connection of the cortex and the long-distance connection of different areas. The role of loops is still unclear. Some scientists suspect that loops are used to fill in missing data or to adjust features based on attention from top to bottom.
Although the enhanced CNN with a loop structure can be used to solve relatively simple occlusion or prediction tasks, these models can neither adapt to complex tasks (feedforward CNN can solve), nor can they explain neurofeedback. In fact, due to the complexity and diversity of target recognition, many images in ImageNet are of uneven quality, so it is possible to use the above-mentioned loop processing mechanism. And recently many efficient solutions to ImageNet have proposed using the same structural motif in multiple layers. So we choose to study whether the loop structure can improve the classification performance of the model on the ImageNet dataset. Although other work uses the output of CNN as the input of RNN to solve visual tasks, here we combine the loop structure with CNN itself, because this type of structure is very common in neuroscience.
Model structure
In order to study the spatial structure of the convolutional RNN, we use the TensorFlow library to enhance the standard CNN with local and long-distance loop structures, as shown in the figure:
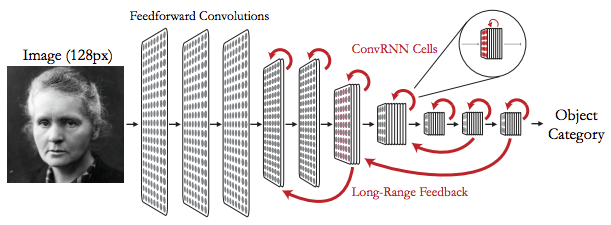
Convolutional recurrent network contains a combination of local loop and remote feedforward connection
In each layer of the convolutional RNN, the feedforward input from the higher layer is resized to match the spatial dimension of the feedforward input. Both types of input are processed by standard 2D convolution. If the layer has any partial loops, the output will be input to the next loop unit.
In this work, all forms of loops are fed forward with parameters added to the base model. Since this can improve the performance of the model, we trained two models that contrast with the convolutional RNN:
Feedforward models with more convolutional filter layers (wider) or models with more layers (deeper) to match the number of parameters in the loop model;
The convolutional model is unfolded and copied, and the number of parameters is the same as the original convolutional RNN.
Experimental results
New RNN structure improves task processing performance
We first tested that enhanced CNN with standard RNN units (such as vanilla RNN and LSTM) can improve the performance of ImageNet target object recognition. The comparison between the two is shown in the figure:
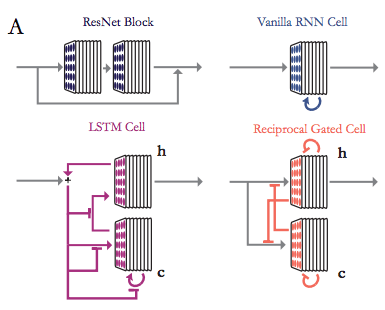
It turns out that the accuracy is slightly improved on the six-layer feedforward like AlexNet.
But there are two problems with the loop structure here. First, due to the increase in the number of single parameters, these convolutional RNNs have not improved much in detection performance. Secondly, making the feedforward model wider or deeper will improve the performance more than simply increasing the standard RNN unit, but with fewer parameters. This shows that although the standard RNN structure is suitable for many tasks, it is not suitable for tasks in deep CNN.
After our research, we found that this is because of the lack of two key attributes in the standard RNN:
Gating, that is, the value of the hidden state determines how much of the next input can be passed, retained or discarded;
Bypassing, that is, a zero-initialized hidden state allows feedforward input to pass through the next layer.
Importantly, both of these features are to solve the problem of vanishing gradient. So we deployed the two features into the loop structure. The specific results are shown in the figure:

After optimizing the hyperparameters of the deeper loop structure, we simulated the primate abdominal flow (participated in object recognition) nerves with convolutional RNN.
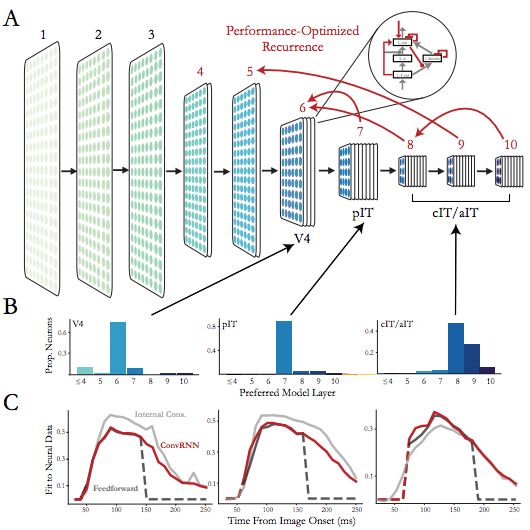
Conclusion
In fact, this paper describes in detail that the recurrent unit in CNN can effectively improve performance in target recognition. Our findings can increase the probability of different local recurrent structures corresponding to different behaviors in the brain. We believe that by applying this method to CNN, we can improve the performance of many existing methods. Future experiments will explore whether different tasks can replace the supervised target identification on the neural feedback of the convolutional RNN. It will also test whether the model can be lower than other forms of noise.
A business tablet must have powerful business functions. At present, users use tablet products more for entertainment, and insufficient development of commercial value has become a major factor restricting the development of tablet computers. Many far-sighted terminal manufacturers have set their sights on the business tablet field.
Generally speaking, when business users choose tablet PC products, they still focus on "regular items" such as processor, battery, operating system, and built-in applications, especially office software applications, which are a good helper for business users.
First of all, there must be powerful office software such as customer management software, which can record customer data and related information anytime, anywhere. There is also a need for powerful marketing software, software marketing, reducing manual intervention, and one person can handle all the publicity and customer information.
Business Tablet,4k Tablet,5G Tablet
Jingjiang Gisen Technology Co.,Ltd , https://www.jsgisengroup.com