Improved word pair detection by integrating path-based methods and distributed methods
Joint compilation: Zhang Min, Gao Fei, Chen Chun
Summary
In natural language processing (NLP), clarifying the relationship between words is a key task, and this is also emphasized in a document that uses two complementary methods. The distributed approach: its supervised variant is the best task executor at the moment; the path-based approach: it has only received a little research attention. We have found that the improved path-based algorithm—whose dependency path is encoded by the recursive neural network—should achieve ideal results compared to the distributed approach. Then, we extended the method used to integrate path-based and distributed signals, which significantly increased the performance on this task to the current best level.
1 Introduction
In natural language processing tasks, word-pair relationship is a very important lexical semantic relationship. For example, knowing that Tom Cruise is an actor helps the question answering system answer questions like: "Which actor participated in Scientology?" Semantic categorization, such as WordNet, defines word-to-word relationships between lexical types, but they are limited in scope and domain. Therefore, automated methods have been developed to determine whether, for a given word pair (x,y), y is the word pair of x, depending on their generation in large corpus.
For decades, this task has had two types of solutions: distributed and path-based. In a distributed approach, whether or not y is a word pair of x depends on the distributed representation of these terms. Later, with the embedding of popular vocabulary, most attention has been shifted to supervised allocation methods, where each word pair (x,y) is represented by a combination of embedded vectors of some words.
Compared to the distributed approach (determining the context based on x and y alone), the path-based approach is based on the co-occurrence of x and y in the joint corpora of grammar and vocabulary paths. Hearst defines a small set of frequent paths to represent word-pair relationships. For example, Y, X, Snow et al. express each word pair (x, y) as a multiple set of path-dependent links, connecting them to the corpus. Together, and based on these characteristics, a classifier was trained to predict word-to-word relationships.
Using separate paths as features will result in a huge, sparse feature space. Although some paths are rare, they are also composed of some unimportant components. For example, ""Spelt is a species of wheat" and "Fantasy is a genre of fiction" produce two different paths: X be species of Y and X be genre of Y, but both imply X is-a Y The only solution is to use the part of the tag or wild card they spoke to replace the vocabulary on the path, as the PATTY system does.
Overall, the performance of the best path-based approach is worse than the allocation approach. A major limitation of the path-based approach is that they require that word pairs occur together in the corpus, limiting the recall of these methods. However, distributed methods do not have such a requirement. They usually do not accurately detect a particular semantic relationship such as a word-pair relationship, and have a very high performance in detecting general semantic similarities between words. Although these methods seem to be complementary, there are many efforts to integrate them.
In this article, we present HypeNET, a combination of path-based and distributed methods for contextual context detection. Inspired by recent research on tiered aspects, we have used a long-term, short-term memory (LSTM) network to encode dependent paths. In order to create enough training data for our network, we followed the previous method of building a data set based on knowledge resources.
First, we show that the path-based approach, in itself, has greatly improved performance compared to previous path-based approaches, and has achieved the same performance as the distributed approach. Our analysis shows that the neural path representation can ensure better generalization. Although poor generalization, such as replacing a word by its POS tag, captures the syntactic similarities between the main paths, HypeNET also captures semantic similarities.
Then we showed that we can easily integrate distributed signals in the network. The integration results show that distributed and path-based signals actually provide supplementary information. Compared to each individual model, the performance of the combined model improves to 14F1.
2. Background
We introduce two main methods for word pair relationship detection: distributed methods, and path-based methods. Then we discussed the application of recursive neural networks in relational grade-related tasks.
2.1 Distributed Method
Word-pair relationship detection is a commonly used distributed method. In this method, a word pair that detects whether y is x based on the distribution of two terms indicates, for example, a context in which each term appears separately in the corpus.
The previous method developed an unsupervised method of word pairing, starting with a symmetric similarity measure and following a directional approach based on distributions containing hypotheses. This hypothesis holds that the context of a hyponymic word is expected to include those hypernyms to a large extent. The recent work introduced new measures. It is based on the assumption that the most typical linguistic context of hypernym is less information than hyponym.
Recently, the focus of distributed methods has shifted to monitoring methods. In these methods, (X, Y) terms are represented by a feature vector and these vectors are trained on the classifier to predict the word-pair relationship. There are several ways to represent a term pair as a combination of each term embedded in a vector: a cascaded x-vector ⊕y vector, a difference y vector-x vector, and a dot product x vector y vector. Using neural vocabulary embedding, these methods are easy to apply and produce good results.
2.2 Path-based methods
There is a method of detecting word-to-word relationships between the term pairs (x,y), taking into account the lexical-grammatical paths (interfaces where x and y co-occur in large corpus). The automatic detection and tracking of superordinate words from free text is based on a path that was first proposed by Hearst (determining a small set of lexical syntax paths indicating contextual relationships, such as Y such as X, X and other Y).
In later work, Snow et al. learned to detect contextual relationships. Rather than searching for specific paths indicating contextual word-pair relationships, they express each (x,y) language pair as multiple sets of all dependent paths—connecting x and y in the corpus and training a logistic regression classifier based on other paths. , predict whether y is a hypernym.
Paths indicate that the upper relationships are those that are assigned high weight by the classifier. The path determined by this method will be proven by Hearst to include these findings, and moderately improved performance. The later changes of the Snow et al. method will be used for many tasks such as: classification construction, analog recognition, and definition extraction.
One of the main limitations of relying on lexical syntax paths is the sparsity of the feature space. Since similar paths may differ, at the lexical level, summarizing this change to more abstract paths can increase recalls. The PATTY algorithm is used to summarize the classification of long-term relationships from free text. For each path, they added a broad version, in which a subset of the words along the path would be replaced, either by their POS tag, or their ontological type or wild card. This generalization will increase the recall while maintaining the same level of accuracy.
2.3 RNNs for Relationship Classification
Relationship classification is a related task. Its goal is to represent two similar target items in a given sentence to a predefined relationship class. To illustrate, consider the following sentence from the SemEval-2010 relational classification data set: "[Apple] e1 is in [basket] e2." Among them, the relationship between target entities expresses: content−container (e1, e2).
The shortest path of dependencies between target entities proves to be the information for this task. Recently, deep learning techniques have shown good performance in capturing indications in such paths.
In particular, several papers have shown that using recursive net neural networks (edge-to-edge processing dependent paths) improves performance. Xu et al. applied a separable long-term short-term memory (LSTM) network for each sequence word, POS tag, dependent tag, and lexical network along the path. The output of the max-pooling layer in the LSTM is used as the input to the network to predict the classification. Other papers suggest mixing additional network architectures to further improve performance.
Although both relationship classification and word-pair relationship detection involve the identification of semantic relationships (holding a pair of terms), they differ in their main aspects. Relationships should be expressed in a given text in relational classification, whereas in meta-relationship detection, the goal is to identify a general lexical semantic relationship between terms (terms held in many contexts). Therefore, the relational classification term pair is represented by a single dependent path, whereas in the context detection it is represented by multiple sets of all dependent paths (occurring in the corpus).
3. LSTM-based context detection
We proposed HypeNET, an LSTM-based method for context detection. We first focus on improving the path representation (Section 3.1), then integrate distributed signals into our network, and finally produce a combined approach (Section 3.2).
3.1 Path-based network
Similar to the previous work, we represent each of the dependent paths as a sequence of edges (leading x to y in the dependencies). Each edge includes part of the speech tag of the argument and source point, a dependent label, and the direction of the edge between the two following points. We define each edge as lemma/POS/dep/dir. The description is shown in Figure 1.
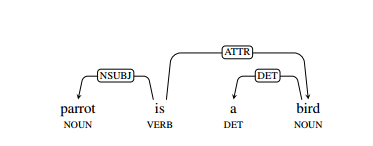
Figure 1: An example dependency tree for the sentence "parrto is a bird", where x = parrot, y = bird, and the symbol can be represented as X/NOUN/nsubj/< be/VERB/ROOT/-Y/NOUN/attr/>.
Instead of treating the entire dependency path as a separate feature, we also use the long-term short-term memory (LSTM) network-encoded edge sequence. The vectors obtained from different given (x,y) pairs of paths are common, and the resulting vectors are used for classification. Figure 2 depicts the overall network structure (described below).
Edge representation. We represent each edge by a vector of concatenations:
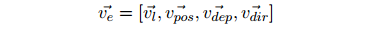
The vector vl represents the embedded vector of the argument, the vector vpos represents the part of speech, the vector vdep represents the dependency tag, and the vdir represents the dependent direction (path along x to y).
Path representation. For the path p consisting of the edges e1.........ek, the edge vectors ve1...vek are successively placed into the LSTM encoder, generating the vector Op representing the entire path p. . The LSTM structure captures the time pattern in the sequence very efficiently. We hope that the training program will cause the LSTM encoder to focus on the path part - more information is used for the classification task and other information is ignored.
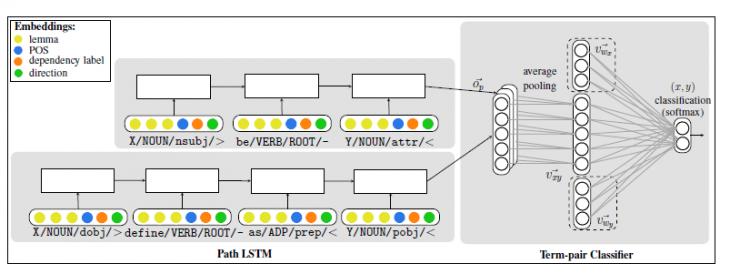
Figure 2: Illustration of word pair classification. Each word pair is represented by several paths. Each path consists of a series of edges, each of which consists of four parts: a term, a POS, a dependency tag, and a dependency direction. Each edge vector is stored in the LSTM according to the sequence, and finally a path embedded vector Op is generated. The average path vector becomes a pair of feature vectors and is used to classify the term pairs. The dashed vector vwx, vwy is used to refer to the integrated network described in section 3.2.
Word pair classification . Each (x,y) word pair is used to represent the multiple sets of lexical syntax paths that link the x,y in the corpus together with the supervision of all word pairs. We use the average weight of the path vector for each word pair to represent the word pair (x,y). In the calculation process, we averagely distribute the path vectors of this word pair:
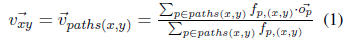
Where fp(x,y) represents the frequency of o in paths(x,y). We then store this path vector in a single-layer network that uses dichotomy to determine that y is the upper word of x.
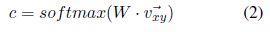
For a two-dimensional vector, the sum of its components is 1. If c[1]>0.5, we divide the word pair into affirmative pairs.
Implementation details . We use PyCNN to practice the network. We use mini-batch 10 and Adam update rules combined with gradient-based optimization methods to minimize cross-entropy (Kingma & Ba, 2014). By reducing component embedding, application normalization is achieved. We use the validation set (refer to the appendix for hyperparameter values) to adjust hyperparameters (learning rate and dropout rate).
Using the pre-trained GloVe word embedding method used on Wikipedia to implement the process of initializing the entry of words (Pennington et al., 2014). We try to use the 50-dimensional and 100-dimensional embedded vectors to select the vectors that yield better results in the validation set. Other entries with embedded vectors and vocabulary are initialized randomly. In the training process, all embedded vectors are updated.
3.2 Integrated Network
3.1 The presented network classifies each term pair (x,y) according to the path of x,y in the corpus. Our goal is to improve our previous path-based approach to the detection of supreme and inferior relationships. Section 6 shows that our network does exceed the previously used detection methods. However, since path-based and distributed approaches are considered to be complementary, we propose a simpler approach that integrates distributed features into the network.
We have expanded this network to take into account each branch information it belongs to. Inspired by the supervised distributed cascading method (Baroni et al., 2012), we simply relate the x,y, lexical embedding to the (x,y) feature vector and redefine it to vxy:
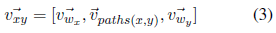
Among them, vwx, vwy is the lexical embedded vector of x, y, and vpaths (x, y) is the average path vector in the equation. Using this method, each word pair (x, y) can be represented by its distribution feature, x, y, and its path-based feature.
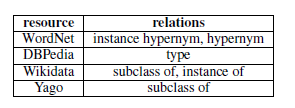
Table 1: Top-to-bottom relationships in each vocabulary source
4 data sets
4.1 Creating an Instance
Neural networks often require a large amount of training data. However, the existing upper-word data sets, such as BLESS (Baroni & Lenci, 2011), are relatively small. Therefore, we create a data set through the common method of remote monitoring of knowledge resources (Snow et al., 2004; Riedel et al., 2013). Snow et al. (2004) created their own database based on word-word semantic relations. Following the method of creation, we selected the following semantic relationships from the following data sources: Wordnet (Fellbaum, 1998), DBPedia (Auer et al., 2007), Wikidata (Vrandecic, 2012), and Yago (Suchanek et al., 2007).
All instances in our data set, both positive and negative, are word pairs that have at least one direct connection to one of the data sources. These linguistic resources contain hundreds of semantic relationships, some of which have varying degrees of context. In order to avoid the emergence of problematic relationship types, we consider only those non-controversial supra-paragraph relationships that are considered positive examples (see Table 1). These uncontroversial supra-subordinate relationships are our papers from Shwartz et al. (2015). Selected in the manual selection.
Word pairs associated with other semantic relationships (including synonym relationships) are treated as negative instances. By treating word pairs that are related to each other rather than randomness as negative examples, we can test the effectiveness of our choice of methods in distinguishing between the up and down meaning relationships and other types of semantic relationships. In our data set, the ratio of affirmative and negative word pairs remained at 1:4.
Similar to the selection method of the word pairs by Snow et al., our dataset only includes the word pairs that appear in the corpus. This will require that each word pair has at least two different dependent paths.
4.2 Random Segmentation and Lexical Data Set Segmentation
As our main data set, we use the standardized stochastic partition method, where training accounts for 70%, testing accounts for 25%, and validation sets account for 5%.
Levy et al. (2015) pointed out that the supervision of distributed lexical reasoning methods has a tendency to use “vocabulary memoryâ€, that is, to a large extent, they learn the nature of a single vocabulary in word pairs: whether the vocabulary is a typical upper word Instead of learning the relationship between the two vocabularies. For example, if the training set contains word pairs such as (dog, animal), (cat, animal), (cow, animal), and all of these word pairs are annotated as positive word pairs, the algorithm may be able to use animal as Make a new word and treat any new (x, animal) word pair as an affirmative word pair, regardless of the relationship between x and animal. Levy et al. (2015) proposed to split columns and test sets so that each column and each test set contains a characteristic vocabulary (“lexical segmentationâ€) to prevent over-fitting of vocabulary memory models.
In order to investigate the above-mentioned behavior, we will also present the lexical segmentation results of our dataset. In this way, we separate the training, testing, and validation sets so that each part contains a distinctive vocabulary. It is noteworthy that we use methods other than those of Levy et al., and Levy et al. only split the columns and test sets, mainly using the verification set. The reason why we adopted a different approach than our predecessors is that we noticed that when the validation set contains vocabulary in the column, when adjusting hyperparameters, vocabulary memory will have a positive impact on the model, and eventually in the lexical features test set. Calculations produce undesirable performance results. When each set contains a feature vocabulary, parameters need to be adjusted to avoid the lexical memory phenomenon. When calculating in the test set, a more ideal result will be obtained. In vocabulary segmentation, we tried to keep the ratio roughly 70/25/5. The data set size created above will be presented in Table 2.
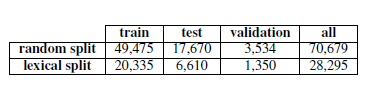
Table 2: Number of instances in each dataset
Indeed, training a vocabulary segmentation dataset model may produce a more universal model that will more effectively handle vocabulary pairs containing two invisible vocabularies in the reasoning process. However, we believe that in the ordinary application process, the reasoning process should design an invisible word pair (x, y) in which x and/or y have appeared in separate corpora. Training models that use stochastic partitioning may use a model that displays the probability of a top-to-bottom relationship or a synonymous relationship. This prioritized probability information will play a useful role in the reasoning process.

Exhibit 3: Examples of Inducing x as y
5. Baseline
We compare Hype NET with several of the best methods to detect the hyponymy relationship, as described in the second part: path-based methods and distributed methods. Since different jobs use different data sets and corpora, we chose to replicate the baseline instead of comparing it with the reported results.
Since May 2015, we have adopted a Wikipedia dump as a corpus of all methods and used spaCy to analyze it. We use the validation set for model selection, aiming to adjust the hyperparameters of each method. The optimal hyperparameters will be presented in the appendix.
5.1 Path-based approach
Snow . We refer to the original article and extract the shortest path between the four edges, or rely on shorter paths between the words in the tree. Similar to the method adopted by Snow et al. (2004), we add “satellite edge†to each path, ie, those single words that have long been separated from the dependent path. These words are either connected to x or connected to y to form “summarizing Yâ€. The path to X". The number of these feature paths is 324,578. We use the x2 feature selection method to save 100,000 information-rich paths and train using a logistic regression classifier.
Induction . We will also compare the approach used with the baseline using a common dependency path. In this process, a power set of all possible induction methods is generated, including the original path. For example, the total number of features summarized is 2,039,220. Similar to the first baseline, we use the feature selection method. This time, we reserve 1,000,000 paths that contain the maximum amount of information, and practice a logistic regression classifier based on the ordinary path.
5.2 Distributed Methods
Unsupervised approach. SLQS (Santus et al., 2014) is an entropy-based approach to the detection of hyponymy relations. It is reported that this detection method is due to the state-of-the-art unsupervised approach used previously. The original article was evaluated in the BLESS data set, which consists of a large number of common words. The SLQS setup method that includes both rare words is used to detect our data set, resulting in lower performance results. As a result, we received help from Enrico Santus. After adjusting the system, he provided us with the results of our dataset testing in SLQS.
The verification set is used to adjust the threshold for dividing a word pair into positive pairs, and the threshold of the number N of most relevant contexts per word. In the original article, the number of contexts associated with each vocabulary is set to N, and after adjustment, the number is set to the number of contexts above the LMI zero score and the minimum value between N. In addition, the SLQS score does not increase as the cosine of similar scores between vocabulary changes.
Regulatory approach . To represent word pairs with distributed features, we have tried several state-of-the-art methods. We downloaded several different models of pre-training embedding methods and trained a number of classifiers: logistic regression, SVM, SVM with RBF hubs. According to Levy et al. (2005), the last classifier has the best performance in this group of classifiers. We use the validation set selection model to select the optimal vector, the best method and the regular factor (see appendix).
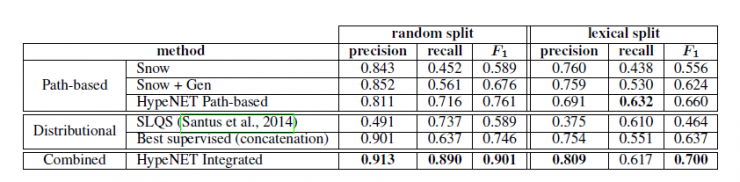
Table 4: Based on two variants of the data set, the performance of the upper and lower bit detection is compared between the method we used and the line-based baseline and the advanced distribution method – both lexical segmentation and random segmentation are used Train, test and confirm.
6. Results
Table 4 shows the HyperNet performance score and its baseline. HyperNet Path-based is a path-based recursive neural network system. HyperNet Integrated is a composite method. Comparing the path-based approach to the generalization path can increase the repetition rate but also maintain the same level of accuracy. Nakashole et al. found this phenomenon and conducted a reassessment. HyperNet Path-based outperformed the other two Path-based benchmarks because of its significant improvement in repeatability, despite a decrease in accuracy. The repeated improvement is due to the promotion of the route, as shown in section 7.1.
Considering the method of allocation, the supervised SLQS baseline performed less well on our dataset. The reason for the lack of precision lies in the insufficiency of distinguishing between upper and lower nouns. This phenomenon is also very common in our data sets, which in turn causes many false positive word pairs, such as (zabrze, poland) and (kibbutz, israel). In each data set, we sampled 50 false-positive pairs, and found that 38% of false-positive pairs appeared in random splits and 48% of false-positive pairs appeared in lexical segmentation, and were all partial word pairs.
Based on the results reported previously, supervised embedded methods perform best on our dataset. HyperNET Path-based performance followed, achieving optimal results. Adding distributed features in our approach shows that the two methods are indeed complementary. In terms of data segmentation, HypeNET Integrated and HypeNET Path-based perform differently. In addition, the distributed method is also the same, with substantial differences, and the p-value difference is about 1% (paired tc test).
We re-evaluate supervised distributed methods that perform poorly in lexical segmentation. It was further observed that there was a similar decrease in the use of HypeNET, but this was not the result of a vocabulary memory but was due to over-generalization.
7. analysis
7.1 Quality Analysis of Paths Learned
By comparing the significant differences in the indicative paths learned by the path-based approach, we analyze the generalization capabilities of HypeNET in the path structure. The reason we do this is to find a path that can promote high scores for classification in the dataset. Based on the route-based baseline, the data regression classifier can learn the most weighted features. In the LSTM-based approach, it is not easy to directly identify the most indicative path. We evaluate the contribution of a particular path p in classification, by treating it as the only path that appears in the term pair and calculating its true mark score from the classification aspect.
Snow's method is to learn a specific path. This is a well-known pattern. For example, X comes from Y. Although Snow's method relies on a verbatim path, which limits the repetition, Snow's generalized version can make a brief generalization. For example, X is the verb form of Y. Obviously, this path is too extensive, and almost all the verbs are assigned to it, resulting in no indication of the path (for example, X comes from Y). By working hard to learn this approach can avoid this generalization and reduce duplication. HypeNET provides a better midpoint. It can better plan the path by learning additional similar semantic paths. For example, X becomes a form of Y or X is a form of Y. The behavior of these additional example paths will be explained in Table 5.
We also noticed that our model can still learn a wide range of paths despite random divisions, for example, X is published in Y (is derived from the following example: Y = magazine) or X is produced by Y ( Y=movie), only X and wide path relationships can be known in lexical segmentation. We have noticed that X is a relatively "noisy" path and may appear in certain scenarios, but it does not specify a wide range of contexts (for example, chocolate is a big issue in terms of children's health.) This model can be based on generic paths, identifying invisible top-to-bottom relationships, and it also proves that over-generalization can affect performance, as shown in Table 4. As discussed in Section 4.2, we would suspect that in this context, the relationship between the two is invisible and it is not common to use training settings.
7.2 Error Analysis
We classify false false positives, based primarily on terms used to establish the relationship between each of the data sets in the resource. We classify semantic relations from different aspects to broad classifications. For example, synonyms include aliases and Wikipedia redirection. Table 6 shows us the distribution of semantic relationships between false positive pairs.
More than 20% of the errors stem from the confusion between upper and lower relational words or synonyms, and it is very difficult to identify the relationship.
An additional 30% of the term pairs will reverse the upper and lower word pairs (y is the lower word of x.) Examining these words and instances will reveal that these word pairs are approximately synonymous but not the relationship between them. Not so clear. For example, fiction is a hypernym of story in WordNet, but we often think of it as a synonym.

Table 5: The examples obtained through the study of each method have an indicative path, and at the same time, the corresponding pairs of actual report terms are also selected from the random split test set. Hypotactics are marked in red, hyponymes in blue.
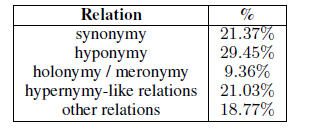
Table 6: Distribution of relationships between each pair of terms between false positive word pairs.

Table 7: Types of missed reports (coincidence): (1) x and y occur simultaneously less than 25 times (the average number of times that each pair of real-state pairs co-occurs is 99.7). (2) x or y are not common. (3) The superior relationship of x is very rare. (4) The (x,y) error annotation is positive.
One possible research direction in the future is to expand our network to classify words and also to classify multiple semantic relations. This classification model can better divide word pairs with similar semantics.
Another notable category is the similarity between the upper and lower positions: In the resources, there are other relationships that can be considered as superordinate words, but because of the strict selection of non-controversial hypernyms from resources, they are often annotated as negative. Examples include Goethe occupations, novelists and Homo, subdivisionRanks, and species.
Finally, other errors often correspond to words that co-occur several times in the corpus. For example, xebec, an animation studio, may incorrectly be classified as a hyponym of an animation.
We sampled 50 omission was incorrectly annotated term negative word pairs and analysis of the main types of errors (see Table 7).
Most of these word pairs only co-occur several times in the corpus. The reason for this phenomenon is that the unusual term (eg, cbc.ca) or the xde hypernym relationship is not common (eg, night, paly). Its main meaning is “Night,†a play written by Harold Pinter. . And this term pair has too many hypernym implied paths, resulting in the classification as negative.
8. Summary
We use HypeNET for hypernym detection, a neural network-based approach. First, we focused on using LSTM to improve path performance. Finally, the path-based model performed better than the previous path model, and matched the previous excellent distribution method. In addition, it is worth noting that the repeated improvement is caused by the over-generalization of similar semantic paths. This previous method is just the opposite. The previous method neither over-generalized the path nor generalized.
Next, we expanded our network by integrating distributed signals, resulting in an additional 14 F1 points of improvement, which in turn proved that the path-based and distribution-based approaches are indeed complementary.
Finally, our framework is directly applicable to a variety of classifications and can be used to classify multiple semantic relationships of word pairs in future work.
Comments by Associate Professor Li Yanjie of Harbin Institute of Technology: It is a key task in the field of natural language processing (NLP) to clarify the relationship between word pairs. This paper proposes a HypeNET method that combines two methods based on path method and distributed method. Context context detection. The paper is inspired by the recent research on tiered stratification. It uses a long-term memory (LSTM) network to encode the dependent paths, thereby improving the path-based approach, resulting in a path-based model that performs better than the previous path model. Well, then we combine distributed signals into this network. This combination confirms that distributed signals and path-based signals do provide complementary information, greatly improving performance. The author also pointed out that the framework seems to be directly applicable to multi-category classifications.
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission. More ACL related information Scan code Focus on WeChat group
