Using Multimodal Methods to Translate Image Subtitles
Joint compilation: Chen Zhen, Zhang Min, Gao Fei
Summary
We propose to improve the statistical machine translation of image descriptions through a multi-modal hub approach that is positioned by visual space. The main idea is to use the target language to perform image detection on the subtitle translation data in the image, and use the most similar image subtitle translation for cross-language translation output reordering. Our method does not depend on the massive parallel data that can be obtained in the domain. Instead, it depends on the large amount of monolingual speech data that can be obtained for image captioning, and uses an advanced convolutional neural network system to calculate the similarity of the image. Our trial evaluation showed an increase in baseline BLEU points.
1 Introduction
Multi-modal data is composed of images and natural language descriptions (hereinafter referred to as subtitles), and has a wealth of information resources, resulting in the recent proliferation of research on integrated language and visual aspects. Recently, a multi-modal language processing process for a shared task in the WMT16 conference has added multilingual aspects. Obviously, multilingual subtitles have practical needs. For example, an automatic machine description of a work of art can generate a digital art catalogue across language barriers based on social and cultural reasons. The multilingual product description is of high commercial interest because it can expand e-commerce transactions into the international market automatically. However, images and monolingual data already include millions of tuples, and the largest multilingual image and caption database known to the author includes 20,000 or 30,002 descriptions in either English or German.
In this article, we will solve the problem of multilingual subtitling from the perspective of statistical machine translation. Compared with previous studies, Kara Pathy and Fei-Fei and Vinyals et al. directly generate subtitles from images. Our goal is to integrate visual information into SMT tubes. The orthogonal information provided by the visual context can avoid the ambiguity of natural language, so it can eliminate ambiguity and guide the translation process by associating images with subtitles. Because the data set includes source language subtitles, images and target language subtitles, but this data set is not available in large numbers, we will instead use large data sets including images and target language subtitles to improve the number of parallel subtitles SMT mode for training.
The subtitle translation can be defined as follows: To translate ei for the target language that generates the image i, the system uses the image subtitle of the image i in the source language fi as input, and also uses the image i. The system can safely assume that fi is related to i. For example, the confirmation of i-related subtitles is not part of the subtitle translation task. Contrary to the reasoning problem of finding ^e=argmaxe(e|f) in context-based SMT, multi-modal subtitle translation will find that ^ei takes both i and fi into account:
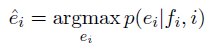
In this article, when we do subtitle translation, we will follow the general cross-language approach to reorganize the framework. In this framework, we will give a pair of source language subtitles and images. The target language subtitles are used for the SMT system's output re-ranking. We currently provide a way to search for subtitles in both target languages ​​and re-rank them by positioning similar parts of the image and the input image. One of these methods is based on the presentation of convolutional neural networks (CNN) for image similarity calculations. Another method is to manually label the object category in the visual space to calculate the similarity. We will be based on a textual comparison of multimodal hub methods and re-ranking methods, in addition to comparing multimodal hub methods with SMT baselines trained on parallel data. Compared to the benchmarks that were trained on the 29,000 parallel subtitles, we found that the visual base point-based reranking improved by more than 1 BLEU point. It is worth noting that our method of reordering does not rely solely on a large amount of parallel data in the domain because such data is not available in the actual scene, for example, the localization of e-commerce. However, in such scenarios, monolingual product descriptions are naturally large, so our job is to describe translations in reality.
2. Related work
Generating subtitles from images alone is a real-world problem that has recently arisen in image processing. The latest method is also based on depth representations for reordering image subtitles by comparing similarities between images and text. The tools used in these studies are neural networks, whose depth characterization greatly improves the quality of image feature representations, enabling powerful semantic analysis of image content. We rely on CNN framework to solve the problems of semantic classification and disambiguation in NLP (natural language processing), and then improve the role of supervision from visual feedback and other aspects. However, we believe that generating captions for images is more difficult than captioning because the relevant information in the source language is not given. Therefore, we will not compare our research with caption generation patterns.
In the area of ​​SMT, Waschle and Riezler propose a framework that combines a large volume of data, monolingual corpus, and machine translation from cross-language information retrieval technologies. The intuition behind generating their methods is to use the SMT system to generate one or more translation hypotheses. SMT can search for matches or find similar sentences in the target corpus. These can in turn be used to enhance translation assumptions to improve the overall impact of translation quality. Our work can be seen as an extension of this approach, and the feedback of visual similarity can be seen as an additional limitation of the cross-language retrieval model. Calixton et al. suggest the use of images as supplementary information for statistical machine translation. They cited examples from new areas because visual information in the new area can help SMT disambiguate and discuss possible features and distances between contextual pictures, but the report does not address the use of visual information throughout the SMT. Parallel to our work, Elliot et al. solved the problem of subtitle translation from the perspective of neural machine translation. Their model is related to our research or completely dependent on available parallel subtitles as training data. But both methods rely on neural networks. They use the visually rich neural codec SMT method, and we follow the subtitle translation retrieval model, using CNNs to calculate visual spatial similarities.
The integration of multi-modal information with NLP is another hot topic in recent research. For example, Silberer and Lapata showed that the representation of word mosaics based on visual characterization performed better than term similarity scores and word classification tasks. Orthogonality of visual feedback Through the development of multilingual settings by Kiela et al., he led the generation of bilingual dictionary-using terminology-specific multimodal representations, obtained through the Google Image Search Engine. Funaki and Nakayama used visual similarity to perform cross-language file searches in multi-mode and bilingual vector spaces, but these vectors were obtained by generalizing typical correlations, greatly reducing the need for parallel data. What they have in common is that the CNN-based similarity information is a “center†or a fulcrum linking corpus. There is a lack of direct parallelism in the two natural language corpora. This is what we have done to solve the subtitle translation problem. Strategy.

Figure 1: Overview of the model structure
3. Mode
3.1. Overview
According to the basic method developed by Waschle and Riezler, we use cross-language retrieval patterns to find sentences in the target language file set C, and use these sentences to re-order the target language translations e translated by the original subtitles f.
The system used in our study differs from that used by Waschle and Riezler in many ways. Instead of a simple or rough two-step search method, our system uses the relevant scoring function in the search matching text set C, and sorts the candidate translations based on the frequency of term occurrences, which shows the TF-IDF related measurement methods. Variants.
The overall structure of our approach is outlined in Figure 1, and contains the following components:
Input: source subtitle fi, image i, target language set of image subtitle pair C
Translation: Generating a unique list of kn-best translations Nfi, using the MT decoder to generate a unique list of Kr-best translations Rfi
Multimodal search: For the translation list Nfi, the Km-most related image subtitle pair Mfi is found in the target corpus C and scored using a heuristic correlation function
Cross-language reordering: Use Mfi's image subtitles to reorder translation list Rfi and apply relevant scoring functions
Output: Determine the best translation assumption by inserting the decoding score dr
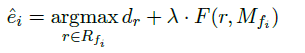
The core idea is that the scoring function S(m,Nfi,i) can determine the three variants of the target search (TSR), all of which can make full use of the above-mentioned procedure. In the baseline and text based reordering mode (TSR-TXT) we use the relevant scoring function STXT. This function is based solely on text and does not take full advantage of multimodal contextual information (eg, it is the closest to the target language search used by Waschle and Riezler). The search information (TSR-CNN) can be enhanced by the visual information from the deep convolutional neural network. This scoring function SCNN basically uses the relevant information extracted from the neural network to perform visual similarity information scoring. Finally, the relevance of these patterns was scored based on the human target classification annotation (tsr-hca) using the scoring function SHCA.
This function makes use of object annotations available for the MS COCO corpus to indicate the effectiveness of our automatic extraction of visual similarity measures. The three models will be discussed in detail later.
3.2. Target Side Retrieval Models
Text-based target-side retrieval model. In the TSRTXT retrieval scheme, the matching candidate value m∈C is scored in the following manner:

Where δ is the Kronecker δ function and Nfi is the best set of Kn translation hypotheses for the source subtitle fi of the image i (scored by the decoder). Typ(a) is a set of functions (unique symbols) generated by the function in subtitle a, tok(a) is the symbol of subtitle a generated by the function, and idf(w) is the inverse document frequency of term w. And the reciprocal of Zm equal to |typ(m)| is the included normalization term used to avoid that the system is biased toward long-term matching candidates (including many low frequency terms). The term frequency calculations were performed on language data provided by the Europarl, News Commentary and News Discussions English datasets (provided by the WMT15 studio). Note that in these models, no image i information is used.
Multi-model target-side retrieval using CNNs
In the TSR-CNN scenario, we use visual similarity information from the deep convolutional network to supplement the textual target TSR model. We formalize this by introducing the semi-positive definite distance function v(ix,iy)→[0,∞) of the image ix,iy (smaller values ​​represent more similar images). The relevant scoring function SCNN is used in the model as follows:

Im is the picture associated with the subtitle m, and d is the cut-off maximum distance, in which the matching candidates are considered to be irrelevant, and b is a weight term, which can control the effect of the visual distance score v(im,i) on the overall score .
Our visual level v is calculated using the VGG16 deep convolutional network model of Simonyan and Zisserman (pre-training on ImageNet). We extract all the input eigenvalues ​​and compute the Euclidean distance between the image from the second to last full-connection layer (fc7) reference image of the model and calculate the image eigenvector. If no neighboring image falls within the distance d, the text-based search program STXT is used as a fallback strategy, which occurs 47 times in every 500 times in our test data.
Target side search by human classification annotation. For comparison, we used the MSCOCO assessment of human classification annotation to evaluate the TSR-HCA search model. In the MSCOCO corpus, each image is annotated with object polygons and classified into 91 common objects. In this scheme, the matching candidate m is scored as follows:
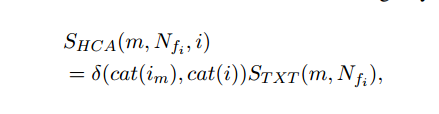
Where cat(i) returns the set of object types for which the image i is annotated. The mandatory category annotation i and the reference image im are strictly matched to the total number, and therefore, the pre-filtering of the STXT in the image subtitles score is performed by strict category matching. In the case where i is annotated with a unique set of object classes, and SHCA does not return a non-zero match candidate, STXT is used as a fallback strategy, which occurs 77 times in our test set every 500 times.
3.3. Translation Candidate Re-scoring
In the three models, the correlation score F(r, MfI) for the reordering model is calculated as follows:
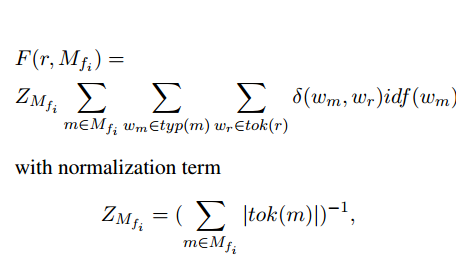
Where r is the translation candidate, and Mfi is the list of km highest target side search matches. Since the model should return a score that reflects r's relevance to Mfi, regardless of the length of Mfi, it is necessary to standardize the number of tags for Mfi. The term ZMfi serves this goal.
4. Experiment
4.1. Bilingual Images - Subtitles Data
We built a German-English parallel data set based on the MS COCO image corpora. From the 2014 training section, randomly select 1,000 images. In the second step, one-fifth of their English subtitles are randomly selected. These subtitles were then translated by a German into German. Note that our experiment uses German as the source language and English as the target language. Therefore, our reference data is not stated by a single individual, but it reflects the heterogeneity of MSCOCO to the greatest extent. This data was split into a development set of 250 subtitles - it was used in the process for testing work, and a test set of 500 subtitles. For search experiments, we only use images and subtitles that are not included in the development set, for a total of 81,822 images (each image has 5 English subtitles). All data is processed and converted to lowercase by cdec, tokenized-anything.pl, and lowercase.pl. For German data, we used the method described by Dyer for compound-splitting and provided cdec utility compound-split.pl for implementation. Table 1 gives an overview of the data set. Our parallel development, development test and test data are all publicly available.
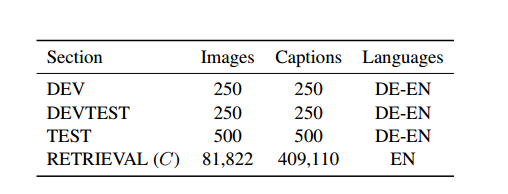
Table 1: Number of images and sentences of image and caption data in MSCOCO used in the experiment.
4.2. Translation Criteria
We compare our method with two benchmark machine translation systems, an out-of-domain data training, and a Domain-adapted system. Table 2 gives an overview of the training data for a machine translation system.
Out-of-Domain Baseline. Our benchmark SMT framework is a free-form grammar using synchronous contexts, phrase-based layered translations, implemented by the cdec decoder. Data provided by Eutoparl, News Commentary, and Common Crawl corpora, as well as WMT15 studio, were used to train translation models, with German as the source language and English as the target language.
As retrieving datasets, training, development and test datasets are all marked and converted to lowercase, we use the same cdec tool. Sentences with more than 80 words, both source and target, were abandoned in previous training. The source text uses compound-split.pl for compound splits.
Use cdec's fsat-align function to extract combinations in both directions and use grow-diag-final-and equal heuristics to balance atools effects. This combination is then used by the cdec grammar extractor to extract synchronous statement free grammars in parallel data.
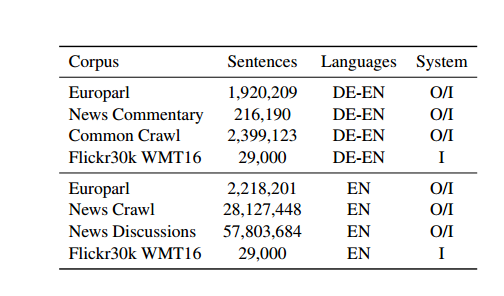
Table 2: Parallel and monolingual data for training machine translation systems. The number of sentences that were not preprocessed for raw data. O/I: Out-of-domain and intra-domain systems, I: Only intra-domain systems.
The target language model was trained on monolingual data from Europarl, News Crawl, and News Discussions (provided by the WMT15 studio, which is also used to evaluate terminology in the retrieval model) from the KenLM toolkit.
For translation quality, we use the Margin Infused Relaxed algorithm (MIRA) to measure the parameters of the translation system as IBM BLEU. To adjust the translation model to extract the final hypothesis list assessment, MIRA performed 20 iterations on the development set and selected the best process for the final test.
Intra-domain benchmarking. We also compare our model with a domain-adapted machine translation system. Apart from the fact that it provides additional parallel training data from the image caption field, the domain-adapted system and the out-of-domain system are identical. For this purpose, we use 29,000 parallel German-English image subtitles (the same number of subtitles for multi-modal machine translation on WMT16 shared tasks). The data set's English subtitles belong to the Flick30k corpus and are very similar to the MSCOCO corpus. German subtitles are professionally translated. English subtitles are also used for additional translation data for the target-side language model. Using this in-domain reference system, we generated a list of kn and translation candidates kr-best.

Table 3: Optimization of the hyperparameter values ​​used in the final evaluation
4.3. Optimizing TSR Hyper-parameters
For each of our search models, we performed a step-by-step exhaustive search of the hyperparametric space on the four system parameters used to develop the IBM BLEU set: the length of kn-best enumerates the entire query used for the search. The number of km-best corresponds to caption retrieval; the length of the final kr-best list is used for ranking; the weighted interpolation λ of the correlation score F is returned by the decoder relative to the probability of translating the hypothesis log. By checking the output of the system for a typical example, the range of exploration of the parameters is manually determined. Table 3 gives an overview of the obtained hyperparameter values.
For TSR-CNN, we initially set the cut-off distance d to 90.0, and manually check the nearest neighbor set to return various maximum distance values. After optimizing the retrieval parameters, we developed an exhaustive search in units of step size from d=80.0 to =100, while keeping other hyperparameters fixed. The result proved that the initial choice d=90.0 was the best value. .
The exploration parameter space is the same for all models, and each model is evaluated on the test set using its own best configured hyperparameter.
4.4. Performance Test
Performing performance tests on different translation quality is performed by using approximate randomization techniques to measure differences in the machine translation system. It was proposed by Riezler and Maxwell and implemented by Clark et al. as part of the Multeval toolkit.

Table 4: Metric scores for all systems and their significance levels reported by Multeval. The Po value is related to the baseline outside the cdec domain, and the Pd value is related to the baseline within the domain. The Pt value and Pc value are related to the TSR-TXT and TST-CNN, respectively. The best results are highlighted in bold.
4.5. Experimental results
Table 4 summarizes the test results for all models in an invisible test set with 500 subtitles. The adjusted domain has greatly improved +4.1 BLEU, and METEOR and TER have been greatly improved. We have found that using a multi-modal hub in the deep convolutional neural networks TSR-CNN and TSR-HCA can improve the target-end retrieval model, which has always been superior in performance to the adjusted domain cdec baseline and text-based The target side retrieves the model TSR-TXT. As a result, these models have been improved in performance, eventually exceeding the general domain adjustment method. The performance of TSR-CNN and TSR-HCA was significantly different from that of BLEU, METEOR, and TER (p<0.05). For all assessment methods, the difference between TSR-CNN and TSR-HCA is not significant. This result proves that we can use the distance metric retrieval method derived from CNN and the retrieval method based on human target classification annotation. Match.

Figure 2: Experimental results of human paired preference ranking based on the joint distribution of two rankings: a+ indicates the preference of people for TSR-CNN accuracy, f+ indicates the preference of people for TSR-CNN fluency, a- indicates that people are within the domain Baseline accuracy preferences, f-, indicate people's preference for baseline fluency within the domain.
The text-based retrieval baseline TSR-TXT has never been significantly superior to the intra-domain cdec baseline, but the performance of the BLEU, METEOR, and TER has been nominally improved. This finding is in fact consistent with the results reported by Waschle and Riezler (2015), which reported improvements in the performance of text-based target-end retrieval models in high-tech, narrow-domain corpora, and even reported on the performance of media diversity corpora. Drops, such as the Europarl Corpus. Our experimental results show that the integration of multimodal hubs into the image enhancement models TSR-CNN and TSR-HCA adds additional visual similarity information, which in turn makes these technologies available for use in the MS COCO, thus confirming that Our hypothesis is that visual information can be used to improve subtitle translation.
4.6. Human evaluation
The difference between the intra-domain baseline and the TSRT-CNN is reflected in the difference in the output of the two retrieval methods in the 169/500 case in the test set. In a double-blind paired preference sorting experiment, the 169 cases were presented to the human with the German source subtitles to facilitate the evaluation of the pairing ranking results. In both systems, the presentation order of subtitles is random. The reviewers were asked to rank the fluency and accuracy of the translation separately. The results obtained are shown in Figure 2. As a whole, people showed a clear preference for TSR-CNN output.
4.7. Examples
Table 5 shows example translations from the cdec baseline, TSR-TXT, TSR-CNN, and TSR-HCA search models, along with active captions, images, and reference translations. The visual information derived from the target end captions of the pivot image can eliminate the ambiguity of the translation results that can be replaced with each other, and can correct wrong translation results.



Table 5: Examples of improved subtitle translation based on multimodal feedback information
5. Conclusions and implications for future work
We have confirmed that in the parallel datasets we have obtained from MSCOCO, in terms of BLEU, METEOR, and TER, combining a multimodal hub with a target-end retrieval model can improve SMT compared to a strong intra-domain baseline. performance. The improved performance of the distance metric based on the deep convolutional network can be compared with the performance improved based on the human target classification annotation. This result further proves the validity of the distance measurement tool derived from CNN. Using our method, SMT can benefit from multimodal context information in some cases. It is especially important that there is no need to use a large amount of in-domain parallel text information. Using only a large number of subtitles that can be easily obtained can improve SMT performance.
The application of deep learning techniques to learn distance metrics has become a hot research field (Wu et al., 2013; Wang et al., 2014; Wang et al., 2015). Although our simple distance measurement method can be comparable in performance to the human target annotation method, the use of this high-level semantic distance measurement for multimodal hubcap translation will have great promise in future research.
The current experimental results are based on only one language pair (German-English) and one Corpus (MS COCO). Like all search-based methods, it is difficult to verify any general viewpoints on various fields, scales, and quality corpuses. This problem is particularly problematic in multimodal cases where subtitles associated with images are diversified in different corpora (Hodosh et al., 2013). In future work, we plan to evaluate the performance of the retrieval methods we use in a more natural context, such as machine translation of subtitles in online multimedia libraries, Wiki Commons, digital art catalogs, and e-commerce localization.
Another future research platform is to improve the performance of the models mentioned by Elliot et al. (2015) in its article by applying important components of neural MTs (such as the "attention mechanism"). For example, the attention mechanism proposed by Bahdanau et al. (2015) influences the translation sequence of source characters to guide the translation process. The article by Xu et al. (2015) uses a similar mechanism to determine which part of the image will affect which part of the generated subtitles. Combining these two types of attention mechanisms in the neural caption translation model will be a natural result of the development of subtitle translation. Although this research direction has exceeded the scope of current research, our search model will provide an information baseline for future research that can be used to refer to the baseline search method used.
Comments by Associate Professor Li Yanjie of Harbin Institute of Technology: This article proposes a method to improve statistical machine translation of image description through multimodal pivots defined by visual space, and solves multi-language subtitles from the perspective of statistical machine translation (SMT). The problem. The core idea is to search the image data with subtitles in the target language, use the subtitles of the most similar images for cross-language translation output reordering, and use the orthogonal information provided by the visual context to avoid the ambiguity of natural language generation. . The thesis method shows that the combination of multimodal hub and target retrieval model can improve the performance of SMT. The improved performance of the distance metric based on the deep convolutional network can be compared with the performance improved based on the human target classification annotation. This result further proves the effectiveness of the distance measurement tool derived from the convolutional neural network (CNN). . This method does not require the use of a large amount of intra-domain parallel text information. It can improve SMT performance by using only a large number of easily-available monolingual image subtitles.
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission. More ACL related information Scan code Focus on WeChat group
