Editor's note: FAIR research scientist Tim Rocktäschel, Oxford University artificial intelligence researchers Jakob Foerster, Greg Farquhar discussed common misunderstandings in machine learning research projects, and gave pertinent suggestions to help the project succeed.

Every year, many students contact us, expressing their desire to carry out short-term machine learning research projects with us. So far, we have instructed many students. We noticed some recurring guidelines, so we wrote this article to share. We believe that the suggestions in this article will be helpful for summer internship research projects or master's thesis projects in the field of machine learning. We do not intend to write a comprehensively guided article, but rather to highlight the misunderstandings we have repeatedly encountered. For example, we will not discuss how to choose a good project, or the general approach to a machine learning research project. Some of the suggestions in this article apply to all machine learning research projects, especially deep learning and reinforcement learning research projects. However, some suggestions are only applicable to short-term projects. These suggestions are very important under the time limit of 3 months, but for doctoral students of 3-5 years, they are relatively not so important.
1 Main misunderstanding
1.1 Assuming that your code has no bugs
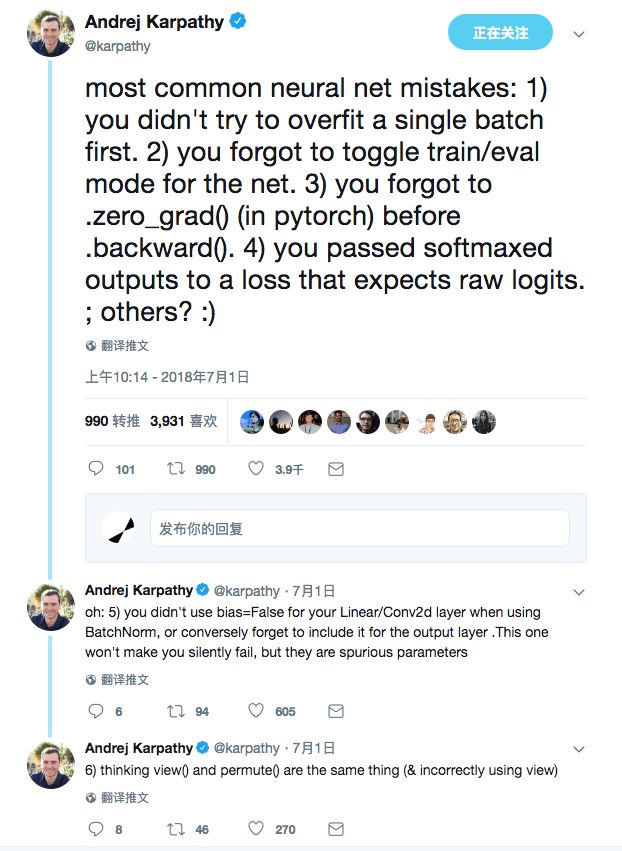
As we all know, machine learning, especially deep learning models and reinforcement learning models, is difficult to debug. Andrej Karpathy has tweeted some common mistakes:
No first attempt was made to fit a single batch.
Forgot to switch the training/evaluation mode.
Forgot .zero_grad() before .backward().
Pass the softmax output to the loss function of the expected original logit.
When using the linear layer/two-dimensional convolutional layer with BatchNorm, the bias=False is not set, or on the contrary, the bias is forgotten in the output layer.
Think that view() and permute() are the same thing (and then wrongly use view where permute should be used).
All of us, even very senior researchers, often make these kinds of mistakes. Because models with bugs can often still learn and generate meaningful output, it is difficult to detect such errors. Bugs may bring subtle changes to your model, and in most cases only appear at runtime. After realizing this, it is a big mistake to assume that your code has no errors. Attitudes to one's own code can often distinguish efficient researchers from inefficient researchers. If your default assumption is that your code may have errors, then you will check for bugs more carefully. Step through the code line by line, carefully checking the intermediate output. If possible, visualize intermediate output. Is the shape of the tensor correct? Are the initialization, cloning, and stripping of tensors appropriate? Detect the gradient during training and pay attention to NaN. Writing unit tests, as well as making the test reproducible by setting the seed of the random number generator, may help. For more tips on neural network debugging, see section 11.5 of Deep Learning (flower book) by Goodfellow et al.
1.2 Just look at the final evaluation measure
Although one of the goals of your project may be to improve the score of an evaluation measure, it is more important to develop a good understanding of how and why the model works. Especially in the early stages of the project, the final evaluation measure contains almost no information that helps iterate and develop algorithms or models. Instead, asking some in-depth questions and developing informative diagnostic methods is helpful. If you introduce a gating or attention mechanism, does your model actually make use of it? Which model innovation you proposed actually contributed to the overall performance improvement? Have you done an ablation test? In order to achieve reasonable performance, how many training samples and how many epochs does your model need? Are these configurations the same as your baseline? Are there any systematic differences between your model's good performance and the poorly performing test cases? How robust is the result to hyperparameter changes? Based on the hidden state of the model, can important features be predicted? Keep in mind that your research and project reports are not mainly to tell the research community about the performance of the state-of-the-art models before that you have made some (weak) improvements, but to contribute to your understanding of this topic. Others in the field want to know what works, what does not work, and which parts of your findings can be applied to their problems.
1.3 Random changes that try to explain inexplicably
Based on these deep learning libraries, it is easy to make the model complex, plus more components, network layers and optimization techniques. However, when you make changes to code or models, you should at least intuitively understand why the changes help. In the same way, when running a test, you should have a clear expectation of its output. What do you expect the resulting image to be drawn to look like? What do you expect they will tell you? These understandings are even more important when you find that the performance of the model is not right. The model's performance is not right, and it is more likely to be a symptom of a bug. In this case, extending the model does not help to find the bug, and may even make it more difficult to locate the problem. Before complicating the model, go to the root of the problem and find the place that may go wrong. Also, don’t forget that your report needs to demonstrate the significance of the changes you made. The reviewers of the report are interested in understanding your thought process. If you can't formalize the research hypothesis and explain to yourself why what you do is effective, then it is likely that no one can do it.
1.4 Overcomplication
We often see highly motivated students who deal directly with difficult problems and try complex solutions immediately. If something goes wrong, it is difficult to analyze the cause of the error. Instead, you should ask yourself: What is the minimization solution that should work? Can the model learn and memorize a small data set? What did the model learn when only a few parameters were used? Can the code be trained on a single training instance instead of a set of samples? What is the simplest generalization we expect to see? What is the simple baseline we expect to fail? What kind of minimal extension should be added to this baseline to make it work?
1.5 Iteration is too slow
The test may take a lot of time. Especially deep learning and reinforcement learning are extremely time-consuming. Therefore, in short-term projects, it is critical not to fall into a slow iteration cycle prematurely. Debug your model based on a simple environment and implement a proof-of-concept implementation that can be run on your personal computer. Sometimes simple matrix operations or grid experiments can help verify your ideas. Sometimes you can directly use the value function of MDP to test algorithm ideas, without having to fiddle with gradient estimation, actor-critic training, etc. When a large-scale test is started, the process of running the test and checking the results is streamlined. Before the test is fully completed, check the results to see if the performance has failed. At the beginning, the investment in infrastructure may take a lot of time, but by the end of the project, you will find it valuable.
2 some suggestions
2.1 Read the background content and related work before starting the project
We often announce projects a few months before the official start date. One of the reasons is that it is very stressful to complete the following content in three months: 1) learning background content and related work; 2) realization and experimentation; 3) writing a good report. Another reason is that the projects we generally propose, if successful, can be published in machine learning journals or conferences. Although we know that students have many things to be busy with, we generally encourage students to at least start reading related literature in advance. Ideally, when you start working on a project full-time, you should know what to do, how it relates to existing methods, and already have some ideas on how to do it. In addition, it is a good idea to familiarize yourself with the machine learning framework of your choice before working on the project full-time (we recommend PyTorch!).
2.2 Use version control
You really should use version control on research code and project reports. There is nothing worse than losing all the hard work before the deadline. If you haven't registered for GitHub, then go to GitHub to register for an account. Students have free private warehouses. If you don't know what version control is, learn it now and you will be grateful for it in the future.
2.3 Based on random repeated evaluation
In academia, you can generally use up to a few GPUs during the project. However, you should not draw immature conclusions from one trial or several trials. This is especially important in deep reinforcement learning. Ideally, you should repeat the experiment several times and, as mentioned earlier, have an understanding of the robustness of different initial conditions and hyperparameters.
2.4 Start writing early and continue writing
If you are doing a master's thesis project, the evaluation of your work will be based on the report you wrote, not on the outstanding work you did that lacked enough time to report clearly. Start writing reports early and don’t underestimate the role of communication research. State your goals, assumptions, and contributions clearly so that readers can understand your progress. Explain your design decisions clearly and discuss your findings clearly. Ideally, you should continue to write reports during the project. This can force you to think carefully about what to do next, and it can also prevent you from missing important information due to rushing to work before the deadline.
2.5 When you need help, take the initiative to seek help
Your instructor is busy at work, but the meaning of the instructor is to help you. If you encounter a problem that cannot be solved, don't postpone it until the next scheduled meeting. Contact your instructor when you need it. Proactively arrange meetings and prepare the results, codes, and report texts you intend to discuss in advance to avoid wasting the time of the instructor. Finally, don't panic! We have all experienced this kind of dilemma and know how daunting it can be, especially when your job opportunities and PhD application depend on the results of the research project. We sincerely hope you can succeed.
Fork Type Terminals,Insulated Bullet Sockets Terminals,Insulated Bullet Terminals,Type Fork Insulate Terminal
Taixing Longyi Terminals Co.,Ltd. , https://www.longyiterminals.com