(1) Hadoop is a software platform for developing and running large-scale data. It can write and run distributed applications to process large-scale data. It is an open source software framework implemented by Java in Appach, which is implemented in a cluster composed of a large number of computers. Massive data for distributed computing (or designed for offline and large-scale data analysis) is not suitable for online transaction processing modes where random reads and writes to several records.
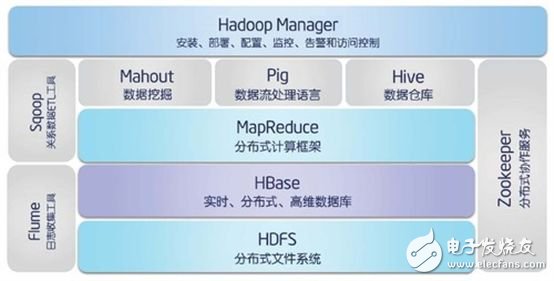
Hadoop=HDFS (file system, data storage technology related) + Mapreduce (data processing), Hadoop data source can be any form, better performance than relational database in processing semi-structured and unstructured data With more flexible processing capabilities, no matter what form of data will eventually be converted to key/value, key/value is the basic data unit. Using function to become Mapreduce instead of SQL, SQL is a query statement, while Mapreduce uses scripts and code, and for relational databases, Hadoop used to SQL has an open source tool hive instead.
(2) Hadoop is a distributed computing solution.
The core design of the Hadoop framework is: HDFS and MapReduce.HDFS provides storage of massive data, and MapReduce provides calculations for data.The process of processing data in Hadoop can be easily understood as follows: The data is processed by Haddop's cluster to get the result.
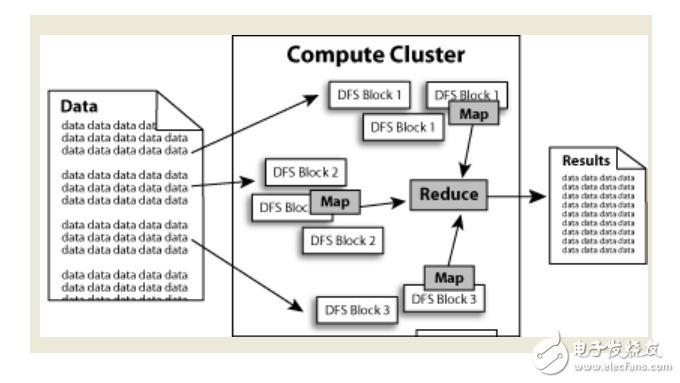
Hadoop is a software framework that enables distributed processing of large amounts of data. Hadoop handles data in a reliable, efficient, and scalable way.
Hadoop is reliable because it assumes that the computational elements and storage will fail, so it maintains multiple copies of the working data, ensuring that the processing can be redistributed for failed nodes.
Hadoop is efficient because it works in parallel and speeds up processing through parallel processing.
Hadoop is also scalable and can handle petabytes of data.
In addition, Hadoop relies on community services, so its cost is low and anyone can use it.
Hadoop is a distributed computing platform that allows users to easily architect and use. Users can easily develop and run applications that process massive amounts of data on Hadoop. It has the following main advantages:
High reliability. Hadoop's ability to store and process data in bits is worthy of trust.
High scalability. Hadoop distributes data and performs computational tasks among the clusters of available computers. These clusters can be easily scaled to thousands of nodes. .
High efficiency. Hadoop is able to dynamically move data between nodes and ensure the dynamic balance of each node, so processing is very fast.
High tolerance. Hadoop automatically saves multiple copies of your data and automatically redistributes failed tasks.
low cost. Hadoop is open source compared to all-in-ones, commercial data warehouses, and data marts such as QlikView and Yonghong Z-Suite, and the software cost of the project is greatly reduced.
Hadoop comes with a framework written in the Java language, so it is ideal for running on a Linux production platform. Applications on Hadoop can also be written in other languages, such as C++.

Hadoop has been widely used in big data processing applications thanks to its natural advantages in data extraction, transformation and loading (ETL). Hadoop's distributed architecture puts the big data processing engine as close as possible to the storage, and is suitable for batch operations such as ETL, because batch results like this can go straight to storage. Hadoop's MapReduce feature breaks down a single task and sends a fragmented task to multiple nodes, which are then reduced to the data warehouse as a single data set.
What can hadoop do?Hadoop is good at log analysis, and Facebook uses Hive for log analysis. In 2009, 30% of non-programmers in Facebook used HiveQL for data analysis; custom filters in Taobao search also used Hive; Doing advanced data processing, including Twitter and LinkedIn, to discover people you might know, can achieve the same effect as Amazon.com's collaborative filtering. Taobao's product recommendation is also! At Yahoo! 40% of Hadoop jobs are run with pig, including spam identification and filtering, and user feature modeling. (August 25, 2012 new update, Tmall's recommendation system is hive, a small amount of try mahout!)
The following examples illustrate:Imagine such an application scenario. I have a sql file with a 100M database backup. I now want to use the grep operation to filter out what I want by regex without importing into the database. For example, there are several ways to record a table with the same keyword. One is to use the linux command grep directly, and the other is to programmatically read the file, and then perform regular matching on each line of data to get the result. It is now a 100M database backup. Both of the above methods can be easily handled.
So if it is 1G, 1T or even 1PB data, can the above two methods work? The answer is no. After all, the performance of a single server always has its upper limit. So how do we get the results we want for this huge data file?
One method is distributed computing. The core of distributed computing is to use distributed algorithms to extend programs running on a single machine to run on multiple machines in parallel. Thereby the data processing capability is multiplied. However, such distributed computing is generally very demanding for programmers and also requires servers. The cost has become very high.
Haddop was born to solve this problem. Haddop can easily make many Linux cheap PCs into distributed nodes, and then programmers do not need to know distributed algorithms and the like, only need to define interface methods according to the rules of mapreduce. The rest is handed over to Haddop. It automatically distributes the relevant calculations to the various nodes and then produces the results.
For example, the above example: Hadoop needs to first import 1PB data files into HDFS, and then the programmer defines map and reduce, that is, defines the file line as key, the content of each line is defined as value, and then Regular matching, if the matching is successful, the result is aggregated and returned by reduce. Hadoop will distribute the program to N nodes for parallel operation.
Then it might take a few days to calculate, and after having enough nodes, you can reduce the time to a few hours.
This is also called big data cloud computing. If you still don't understand, let's take a simple example.
For example, if 100 million 1s are added together to calculate the results, we can easily know that the result is 100 million. But the computer doesn't know. Then a single computer handles the way to do a 100 million cycles each time the result is +1
Then the distributed processing method becomes that I use 10,000 computers, each computer only needs to calculate 10,000 1 additions and then another computer to add the results obtained by 10,000 computers to get the final result.
In theory, the calculation speed is increased by 10,000 times. Of course, the above may be an inappropriate example. But the so-called distributed, big data, cloud computing is probably the case.
(1) The founder of Hadoop is Doug CutTIng, and the founder of the famous Java-based search engine library Apache Lucene. Hadoop was originally used for the famous open source search engine Apache Nutch, and Nutch itself is based on Lucene, and is also a sub-project of Lucene. So Hadoop is based on Java for granted.
(2) Most Hadoop applications developed in other languages ​​use Hadoop-Streaming to interface with the framework. Because Streaming will fork a java process to read and write Python/Perl/C++ stdin/stdout, the overhead will be larger. For larger tasks and long-running tasks, Java is recommended.

Nanning Ousibang Information Technology Co., Ltd. , https://www.ousibangvape.com