At the beginning, dropout means that during the training process of the deep learning network, the neural network unit is temporarily dropped from the network according to a certain probability. Note that for the time being, for stochastic gradient descent, because it is randomly discarded, each mini-batch is training a different network.
Dropout is a big killer in CNN to prevent overfitting and improve the effect, but there are different opinions on why it is effective. Read two representative papers below, representing two different viewpoints, hereby share with you.
â–ŒCombination Pie
The view in the first article in the reference was proposed by the old man Hinton. I will not repeat the position of Hinton in the deep learning world. Just for this position, it is estimated that the viewpoint of this school is "Wudang Shaolin". Note that the name of the party is my own, so please don't laugh.
â–ŒView
The paper starts from the problem of neural network and leads step by step to explain why dropout is effective. Large-scale neural networks have two disadvantages:
Time consuming
Easy to overfit
These two shortcomings are really two big burdens on the thighs of deep learning, one on the left and the other on the right, complement each other, eh, no, stinky. Over-fitting is a common problem in many machine learning. If over-fitting, the model obtained is basically useless. In order to solve the over-fitting problem, the ensemble method is generally used, that is, training multiple models to make a combination. At this time, time-consuming becomes a big problem. Not only is it time-consuming to train, but it is also time-consuming to test multiple models. In short, there is almost a deadlock.
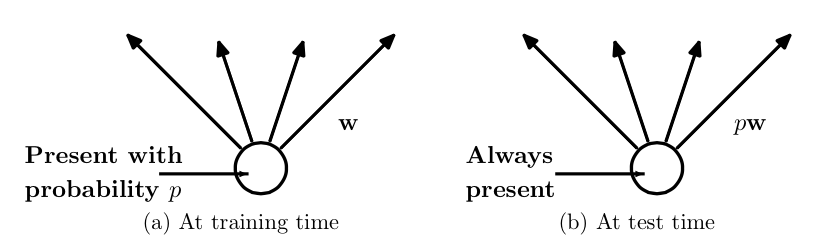
The emergence of dropout can solve this problem very well. Each time you finish dropout, it is equivalent to finding a thinner network from the original network, as shown in the following figure:
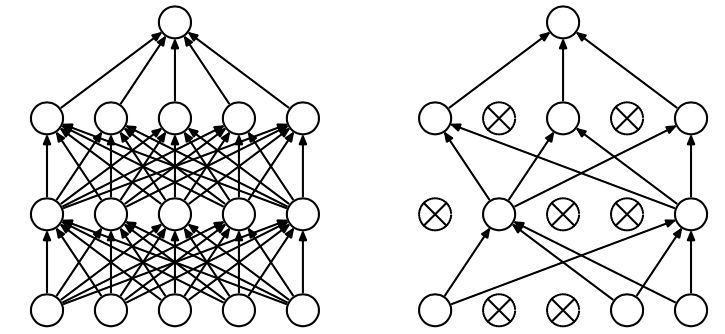
Therefore, for a neural network with N nodes, with dropout, it can be regarded as a collection of 2n models, but the number of parameters to be trained at this time is unchanged, which relieves the time-consuming problem .
â–ŒMotivation Theory
Although dropout is intuitively an approximation of ensemble's classification performance, in practice, dropout is still performed on a neural network after all, and only a set of model parameters are trained. So why is he effective? This requires an analysis of motivation. In the paper, the author made a wonderful analogy to the motivation of dropout:
In nature, among medium and large animals, sexual reproduction is generally performed. Sexual reproduction refers to the inheritance of half of the genes of the offspring from both parents. But from an intuitive point of view, it seems that asexual reproduction is more reasonable, because asexual reproduction can retain large sections of excellent genes. Sexual reproduction breaks down the genes at random, destroying the joint adaptability of a large number of genes.
But after all, natural selection did not choose asexual reproduction. Instead, it chose sexual reproduction. It must be known that natural selection is the survival of the fittest. Let us first make an assumption that the power of genes lies in the ability of mixing rather than the ability of a single gene. Regardless of whether it is sexual reproduction or asexual reproduction, this assumption must be followed. In order to prove the power of sexual reproduction, we first look at a little knowledge of probability.
For example, to carry out a terrorist attack, there are two ways:
Concentrate 50 people, let these 50 people divide the labor closely and accurately, and carry out a big blast.
Divide 50 people into 10 groups, 5 people in each group, and work separately, go to any place to do some action, even if it succeeds once.
Which one has the higher probability of success? Obviously the latter. Because it turned a large team into a guerrilla warfare.
Then, by analogy, the way of sexual reproduction can not only pass down excellent genes, but also reduce the joint adaptability between genes, making the complex large and large gene joint adaptability smaller. Joint fitness of genes.
Dropout can also achieve the same effect. It forces a neural unit to work with other neural units selected at random to achieve good results. Elimination weakens the joint adaptability between neuron nodes and enhances the generalization ability.
Personally add one point: that is that most plants and microorganisms use asexual reproduction, because their living environment changes very little, so they do not need too strong ability to adapt to the new environment, so it is enough to retain a large number of excellent genes to adapt to the current environment Up. But higher animals are different. They must be prepared to adapt to the new environment at any time, so the joint adaptability between genes becomes a small one, which can improve the probability of survival.
â–ŒModel changes brought about by dropout
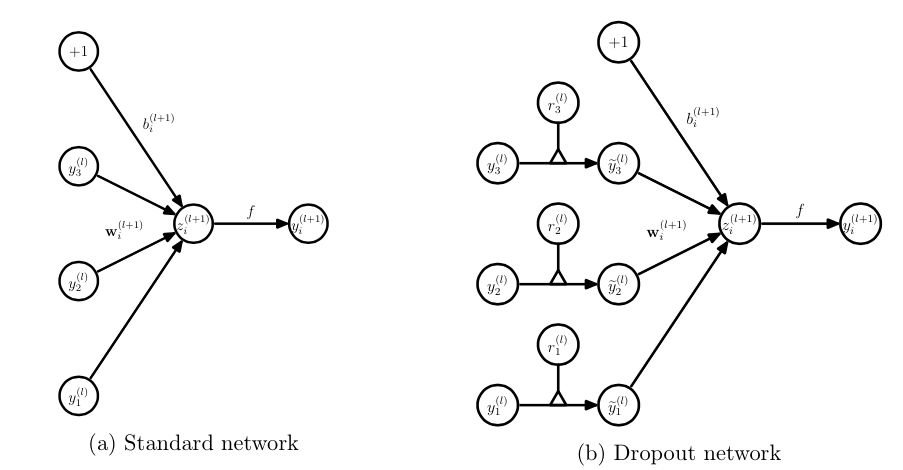
In order to achieve the characteristics of ensemble, with dropout, the training and prediction of the neural network will undergo some changes.
Training level
Inevitably, each unit of the training network needs to add a probability process.
The corresponding formula changes are as follows:
Neural network without dropout
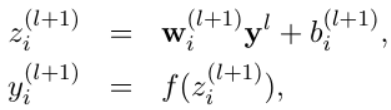
dropout neural network
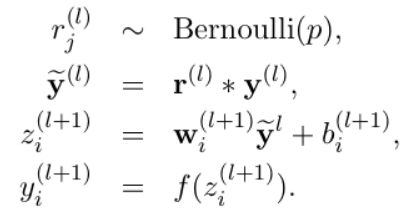
Test level
When predicting, the parameters of each unit should be premultiplied by p.
â–ŒOther technical points in the paper
Methods to prevent over-fitting:
Early termination (when the effect on the validation set deteriorates)
L1 and L2 regularization weighting
soft weight sharing
dropout
Choice of dropout rate
After cross-validation, the effect is best when the implicit node dropout rate is equal to 0.5. The reason is that the network structure randomly generated by dropout is the most when 0.5.
Dropout can also be used as a method of adding noise, directly operating on the input. Set the input layer to a number closer to 1. Make the input change not too much (0.8)
Training process
The max-normalization of the training of the parameter w is very useful for the training of dropout.
The spherical radius c is a parameter that needs to be adjusted. Validation set can be used for parameter tuning
Although dropout itself is very good, but the combination of dropout, max-normalization, large decaying learning rates and high momentum is better. For example, max-norm regularization can prevent parameter blow up caused by large learning rate.
Using the pretraining method can also help dropout training parameters. When using dropout, all parameters must be multiplied by 1/p.
Some experimental conclusions
The experimental part of the paper is very rich, with a large amount of evaluation data.
Another method in maxout neural network, surpassing dropout on Cifar-10
In text classification, the dropout effect is limited. The reason for the analysis may be that the data volume of Reuters-RCV1 is large enough, and overfitting is not the main problem of the model.
Comparison of dropout with other standerd regularizers
L2 weight decay
lasso
KL-sparsity
max-norm regularization
dropout
Feature learning
In standard neural networks, the correlation between nodes allows them to cooperate to fix noise in other nodes, but these cooperation cannot be generalized on unseen data, so overfitting and dropout destroy this correlation. On autoencoder, algorithms with dropout can learn meaningful features (but only intuitively, not quantifiable).
The generated vector is sparse.
Keep the number of hidden nodes unchanged, and the dropout rate changes; keep the number of active hidden nodes unchanged, and the number of hidden nodes change.
When the amount of data is small, the dropout effect is not good, and when the amount of data is large, the dropout effect is good.
Model mean prediction
Use weight-scaling to average predictions
Use the mente-carlo method to make predictions. That is, for each sample, first sample k nets according to dropout, and then make predictions. The larger the k, the better the effect.
Multiplicative Gaussian Noise
Use Gaussian dropout instead of Bernoulli model dropout
The disadvantage of dropout is that the training time is 2-3 times that of a network without dropout.
Further knowledge points that need to be understood
dropout RBM
Marginalizing Dropout
Specifically, the randomized dropout becomes deterministic. For example, for Logistic regression, the dropout is equivalent to adding a regularization term.
Bayesian neural network is particularly useful for sparse data, such as medical diagnosis, genetics, drug discovery and other computational biology applications
â–ŒNoise Pie
The views in the second paper in the reference are also very powerful.
View
The point of view is very clear, that is, when training each dropout network, it is equivalent to doing Data Augmentation, because a sample can always be found, so that the effect of the dropout unit can also be achieved on the original network. For example, for a certain layer, after dropping some units, the result is (1.5,0,2.5,0,1,2,0), where 0 is the unit being dropped, then a sample can always be found so that the result is also in this way. In this way, each dropout is actually equivalent to increasing the sample.
Sparsity
Knowledge point A
First of all, first understand a knowledge point:
When the data points belonging to a particular class are distributed along a linear manifold, or sub-space, of the input space, it is enough to learn a single set of features which can span the entire manifold. But when the data is distributed along a highly non-linear and discontinuous manifold, the best way to represent such a distribution is to learn features which can explicitly represent small local regions of the input space, effectively “tiling†the space to define non-linear decision boundaries.
The general meaning is:
In a linear space, it is sufficient to learn a feature set of the entire space, but when the data is distributed in a non-linear and discontinuous space, it is better to learn a feature set of a local space.
Knowledge point B
Suppose there is a bunch of data, these data are represented by M different discontinuous clusters, given K data. Then an effective feature representation is that after each input cluster is mapped as a feature, the overlap between the clusters is the lowest. Use A to represent the set of dimensions activated in the feature representation of each cluster. Overlap refers to the minimum Jaccard similarity between Ai and Aj of two different clusters, then:
When K is large enough, even if A is also large, the minimum degree of overlap can be learned
When K is small and M is large, the way to learn the smallest degree of overlap is to reduce the size of A, which is sparsity.
The above explanation may be a bit too professional and more confusing. The main idea is that, if we want to distinguish different categories, we must learn the features to be relatively large, and if the amount of data is sufficient, there will be no overfitting behavior, so don't worry. But when the amount of data is small, sparsity can be used to increase the discrimination of features.
Therefore, an interesting hypothesis is here. After using dropout, it is equivalent to getting more local clusters. With the same data, there are more clusters. Therefore, in order to make the distinction greater, the sparsity becomes greater.
In order to verify this data, the paper also did an experiment, as shown below:
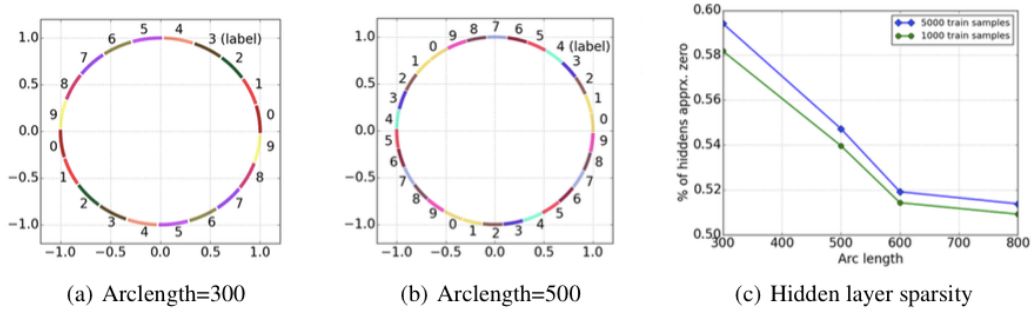
This experiment uses a simulation data, that is, there are 15,000 points on a circle, and the circle is divided into several arcs. The ones on an arc belong to the same category, and there are 10 categories in total, that is, different arcs may also belong to The same class. By changing the size of the arc, you can make more arcs of the same type.
The experimental conclusion is that when the arc length increases, the number of clusters decreases and the sparsity decreases. It is consistent with the assumption.
Personal opinion: This hypothesis not only explains why dropout leads to sparsity, but also explains that dropout makes local clusters more visible, and according to knowledge point A, revealing local clusters is the reason why dropout can prevent overfitting. , And sparsity is only its external manifestation.
Other technical knowledge points in the paper
Mapping the dropout back to the sample to train a complete network can achieve the effect of dropout.
The dropout is changed from a fixed value to an interval, which can improve the effect
When the representation after dropout is mapped back to the input space, a sample x* cannot be found so that all layers can satisfy the result of dropout, but a sample can be found for each layer, so that for each dropout, one can be found Group samples can simulate the results.
There is also a dropConnect corresponding to dropout, the formula is as follows:
dropout
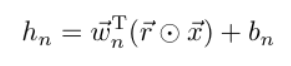
ropConnect
ZGAR Accessories
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

ZGAR Accessories Disposable Pod Vape,ZGAR Accessories Disposable Vape Pen,ZGAR Accessories,ZGAR Accessories Electronic Cigarette,ZGAR Accessories OEM vape pen,ZGAR Accessories OEM electronic cigarette.
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.szvape-pods.com