introduction
This article refers to the address: http://
By September 2013, Google’s self-driving car had successfully traveled more than 500,000 miles under computer control, and there had been no traffic accidents [1]. Google's revolutionary driverless car program aims to improve the safety and efficiency of car driving by using cameras, radar sensors and laser rangefinders (and Google's map database) to monitor and guide the car. Google's driverless car prototype uses a $150,000 robotic component, including a $70,000 lidar system, so there is still a long way to go. In August 2013, Nissan Motors announced plans to launch driverless cars by 2020 to achieve zero traffic accident mortality. The focus of the commercialization of self-driving cars is how to make autonomous vehicles cheaper, more reliable and safer. One of the key technologies for autonomous driving is computer vision, which uses camera-based visual analysis to provide a highly reliable, low-cost vision solution. Although camera-based sensors cost less than other technologies, their processing requirements increase dramatically. Today's system requires us to process images at 30 frames per second and 1,280x800 resolution, usually requiring more than 5 algorithms to run at the same time. Texas Instruments' latest application processor, the TDA2x, is based on OMAP5 technology and features the state-of-the-art Vision AccelerationPac for high efficiency, low cost, programmable and flexible implementation of Advanced Driver Assistance Systems (ADAS) to support 20/20 vision in autonomous vehicles. . The Vision AccelerationPac is a programmable accelerator with dedicated hardware units and custom processes for full programming in a high-level language. It allows visual developers to use some of the advanced features not found in standard processor architectures. Vision AccelerationPac programmable support in high-level languages ​​allows end-car manufacturers to explore algorithmic adjustments and make innovative solutions. This feature is especially important when these algorithms are far from mature, and is also critical to reducing time to market.
Long-eyed car
Statistics from the US Census Bureau show that in the United States, an average of 6 million motor vehicle traffic accidents occur each year. Young people aged 16-24 have the highest traffic accident death rates. The statistics also show that most traffic accidents are caused by human error. It is believed that the addition of visual and intelligent devices to motor vehicles can reduce human error and reduce the incidence of traffic accidents, thus saving lives. In addition, it is believed that the car vision system can help alleviate traffic congestion, improve road capacity, improve vehicle fuel efficiency, and improve driver comfort.
The Advanced Driver Assistance System (ADAS) is a critical step toward the goal of fully autonomous driving. ADAS systems include, but are not limited to, adaptive cruise control, lane keeping assist, blind spot detection, lane departure warning, collision warning system, intelligent speed adaptation, traffic sign recognition, pedestrian protection and object detection, adaptive lighting control, and automatic parking assistance. system.
The camera is a low-cost method that covers many traffic applications and can be used for intelligent analysis. The stereo front camera can be used for adaptive cruise control, monitoring real-time traffic conditions and helping to maintain optimal distance to the vehicle in front. The front camera can also be used for lane keeping assistance, keeping the car in the middle of the lane, as well as for traffic sign recognition and object detection. The side camera can be used for parallel monitoring, blind spot detection and pedestrian perception.
The camera's back-end data analysis capabilities give the car the ability to resemble human vision. The real-time visual analysis engine needs to analyze each video camera frame to extract the correct information to make intelligent decisions. It not only requires superb computing power, it processes data in an instant, so that fast-moving cars can make the right maneuver, and also requires wide I/O to provide visual analysis engine input of multiple cameras, thus achieving synchronous correlation. . Low power consumption, low latency and reliability are also key aspects of automotive vision systems.
TI Technology Implementer - Vision AccelerationPac
TI's Vision AccelerationPac is a programmable accelerator designed to meet the processing, power, latency and reliability needs of computer vision applications in the automotive, machine vision and robotics markets. Vision AccelerationPac includes one or more Embedded Vision Engines (EVE) for programmability, flexibility, low-latency processing and power efficiency, and small silicon area for embedded vision systems for superior performance and price Combine. At the same power level, each EVE has 8 times more advanced visual analysis computing performance improvements than existing ADAS systems. See Figure 1 for details.

Figure 1 Cortex-A15 with the same power budget, the calculation performance is more than 8 times
Figure 2 shows the Vision AccelerationPac architecture.
Vision AccelerationPac has one or more EVEs, a visual optimization processing engine that includes a 32-bit adaptive dedicated RISC processor (ARP32) and a 512-bit vector coprocessor (VCOP) with built-in mechanisms and unique features. Vision-specific instructions for simultaneous, low-overhead processing. ARP32 includes a 32KB program cache for efficient program execution. It also has a built-in emulation module designed to simplify debugging and is compatible with TI's Code Composer StudioTM Integrated Development Environment (IDE). There are 3 parallel flat memory interfaces, each with 256-bit load and storage bandwidth, providing a total of 768-bit wide memory bandwidth (which is 6 times the internal memory bandwidth of most processors), and has a total of 96KB L1 data memory. Synchronous data transfer for very low processing delays. Each EVE also has a local dedicated direct memory access (DMA) for data in and out of the main processor's memory for fast data transfer, as well as a memory management unit (MMU) for address translation and memory protection. . For reliable operation, each EVE also uses single-bit error detection on all data memory and double-bit error detection for program memory. A key architectural level feature is the full concurrency of the DMA engine, the control engine (RISC CPU), and the processing engine (VCOP). For example, it allows the ARP32 RISC CPU to process an interrupt command or execute sequential code while VCOP executes a loop and decodes the other statement at the bottom, and transfers the data without any architecture or memory subsystems stopping working. In addition, it provides embedded support for interprocessor communication through a hardware mailbox approach. In most high-efficiency vision processing, EVE uses only a maximum total power consumption of 400mW to achieve 8GMAC processing performance and 384Gbps data bandwidth.
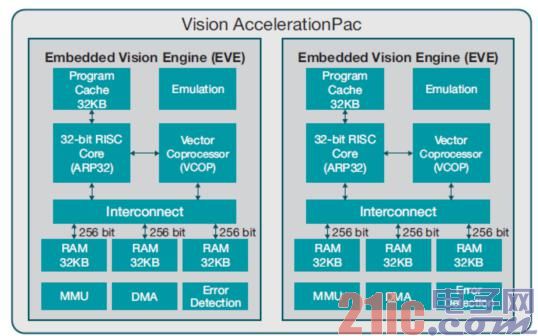
Figure 2 Vision AccelerationPac Architecture
The VCOP Vector Coprocessor is a single instruction multiple data (SIMD) engine with embedded loop control and address generation. It provides dual 8-way SIMDs with 16 16-bit multipliers per cycle, and 8GMACS per second at 500MHz continuous data traffic, which is maintained by rounding and saturation-related load/store with built-in zero-cycle overhead. It can be run from three sources, double the two vector units and calculate 32 32 bits per cycle. VCOP also has eight address generation units, each with a 4-dimensional address function, capable of storing four nested loops and three memory interface addresses, thereby achieving four levels of nested loop zero overhead. It greatly reduces the computational cycle required for iterative pixel operations. Vector coprocessors have many dedicated channels for accelerating histograms, weighted histograms, and lookup tables, and support general computer vision processing levels such as gradient, direction, ordering, bit interleaving/deinterlacing/replacement, panoramic images, and local Binary mode. In addition, vector coprocessors have some specialized instructions for implementing flexibility and concurrent load store operations, designed to accelerate the efficient decoding of non-contiguous memory data by accelerating important decoding and scatter/gather run regions. It minimizes the common data transfers and copies required by traditional image processing programs for ultra-fast processing performance. It is normal to increase the processing speed of various functions related to the standard processor architecture by 4 to 12 times. VCOP itself supports scatter/gather and important processing area functions. Sorting is a common computer vision function that occurs in some versatile situations, such as tracking target feature recognition and dense optical flow search matching. EVE greatly speeds up the custom instruction support ordering, enabling EVE to sort 2048 32-bit data points in 15.2μsec.
The Vision AccelerationPac is fully programmable using the standard TI code generation tool suite, allowing software to be compiled directly and run on a PC for simulation. With TI's real-time operating system BIOS (RTOS), the ARP32 RISC kernel can run C/C++ programs completely. The VCOP vector coprocessor is programmed through a dedicated C/C++ subset of TI's VCOP kernel C build. VCOP Kernel C is a templated C++ vector library that displays various functions of related hardware in a high-level language. Using some standard compilers (eg GNU GCC or Microsoft® MSVC, etc.), algorithms written to VCOP Core C can be evaluated and verified on a standard PC or workstation. It allows developers to incorporate vectorization and verify bit accuracy early in the algorithm development process and test large data sets to ensure robustness of the algorithm. Simply recompile the source code using TI's code generation tools, which run directly on the Vision AccelerationPac. Programs written to VCOP kernel C have many advantages; they are optimized to use the Vision AccelerationPac architecture and instruction set, have a special loop structure that operates on vector data, and there is almost a between C declaration and assembly language. One-to-one mapping, resulting in very efficient code, small code size and memory footprint.
There are more than 100 Vision AccelerationPac programming examples. Compared to VCOP Core C, a simple example of adding an array using ARM® NEON® SIMD shows that in six cycles, ARM can add four 32-bit values ​​to achieve 1.5 cycles per output of the inner loop performance, while VCOP is fully utilized. Its 768-bit load storage bandwidth yields 8 outputs in one cycle. This result is equivalent to the throughput per output of 1/8 cycle, which achieves 12 times the overall cycle-to-cycle speed of ARM.
Vision AccelerationPac's internal EVE ARP32 RISC core is optimized for control code and sequential processing. It supports real-time operating systems running SYS/BIOS, TI, thus providing support for threads, signals, and other RTOS features.
EVE is supported by a full suite of code generation tools, including an optimized compiler or simulator integrated in TI's Code Composer Studio IDE. EVE provides embedded support for non-intrusive performance monitoring through hardware counters. It allows users to monitor multiple performance signals while at the same time running the application and allowing deep monitoring of the application's runtime performance without any code modifications.
Circular traffic sign recognition example using Vision AccelerationPac
Typical visual analysis processing involves several stages (as shown in Figure 3), including image preprocessing and feature detection, correlation object recognition, image and pattern matching, and finally decision making. TI's Vision AccelerationPac is best suited to mitigate intensive calculations in the first three stages of visual analysis processing. Decision making usually includes classifiers, floating-point operations, and matrix transformations, and the C66x DSP core is most effective in their processing. Because of this, Vision AccelerationPac is paired with one or more DSPs in the SoC. As a result, the visual analysis workload is reasonably divided.
TI's TDA2x enables low-power, high-performance vision processing systems. It has two C66x DSP cores and one Vision AccelerationPac, as well as two embedded vision engines (EVE). In addition, it includes a video front end and a car car networking interface. Figure 4 on the next page shows the TDA2xx SoC block diagram.
Below, we will explore how Vision AccelerationPac can accelerate the identification of ADAS circular traffic signs.
Some world circular traffic signs use red circles as the dividing line, so the first step is to extract only red pixels from the YUV422 input data. The second step is to calculate the horizontal and vertical gradients and use the brightness and contrast to confirm the red boundary line. Then, use the Hough transform algorithm to find the circle. Now, using the patterns stored in the database, the images of the relevant regions in the circle are correlated to explain the traffic signs (80 MPH), and finally the decision is made. In this case, the conclusion is a speed limit of 80 mph.
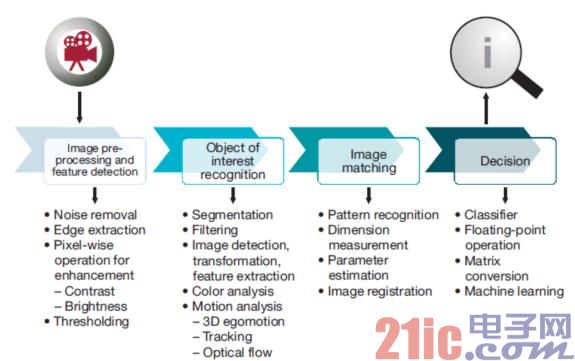
Figure 3 visual analysis processing flow chart
As shown in Figure 5 below, Vision AccelerationPac can efficiently share most of the workload of circular traffic sign recognition processing, including block-based template accelerators based on cross-correlation. The DSP core is used to improve the robustness of the final decision. Using the Hough transform algorithm to find a circle is a highly computationally intensive task, but when using Vision AccelerationPac, the Hough transform algorithm looks for a circle with only 140 bytes of code space, about (1.88*NUM_RADIUS) +1.81 cyc/ Pix processing time periods, where NUM_RADIUS is the radius of the search we select in the Hough space, so its visual recognition time is very short, power consumption is very low, and the silicon area is cost-effective. A full traffic sign recognition of a 720 × 480 image at 30 frames per second requires approximately 50 MHz, which is less than 10% of the EVE period. Maintains a rich processing capability, indicating that an EVE can run multiple visual algorithms simultaneously.

Figure 4 TDA2x structure diagram
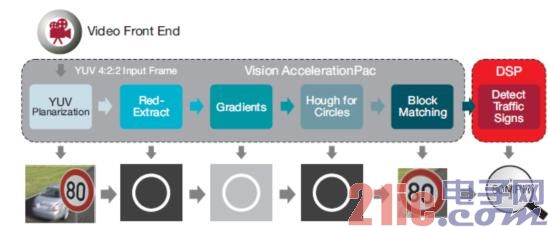
Figure 5: Circular traffic sign recognition using Vision AccelerationPac
Machine Vision AccelerationPac - applications other than car or camera processing
There are many other areas that Vision AccelerationPac can use. In addition to video camera analysis, the Vision AccelerationPac's fixed-point multiplier and hardware channel are ideal for radar analysis processing because it efficiently processes Fast Fourier Transform (FFT) and beamforming algorithms. The time taken to process a 1024-point FFT with Vision AccelerationPac is less than 3.5 μsec. Therefore, radar can be used as a complement to automotive camera systems to detect many different traffic and weather conditions.
The same mechanisms used in automotive vision are also applicable to many other machine vision industries; industrial automation, video security monitoring and warning systems, traffic monitoring and license plate recognition are examples. Vision AccelerationPac can be used to extend DSP applications to solve many of today's visual analysis problems in a more autonomous and efficient way.
in conclusion
Vision AccelerationPac is Texas Instruments' innovative vision analysis solution. With a flexible SIMD architecture that is highly optimized for efficient embedded vision processing, Vision AccelerationPac has very low power consumption and excellent silicon area efficiency. The Vision AccelerationPac, combined with the C66x DSP core, enables floating point and matrix calculations to greatly accelerate the complete embedded vision application processing chain. In addition to being an efficient and reliable architecture, Vision AccelerationPac uses a simple C/C++-based programming model to output very compact code. It means that the system implemented by Vision AccelerationPac has a very low memory footprint, further reducing vision system cost and power consumption. The TDA2x SoC and its Vision AccelerationPac are an ideal platform for intelligent vision analysis of intelligent automotive systems, industrial machines and "visual" robots, which together enhance the quality of our lives.
For more information on TDAx SoC, please visit
references
(1) Google tests driverless cars at Va. Tech
(2) Nissan announces an unprecedented driverless car development plan
Author: Zhihong Lin Texas Instruments (TI), strategic marketing manager, chief architect embedded vision engine Jagadeesh Sankaran and Dr. Tom Flanagan, director of technology strategy
Acknowledgement
Thanks to Stephanie Pearson, Debbie Greenstreet, Gaurav Agarwal, Frank Forster, Brooke Williams, Dennis Rauschmayer, Jason Jones, Andre Schnarrenberger, Peter Labaziewicz, Dipan Mandal, Roman Staszewski, and Curt Moore for their support.
Shenzhen Kaixuanye Technology Co., Ltd. , https://www.iconlinekxys.com